
Why AI Vulnerability Scanners Score 68% in the Lab and Fail in Production
Here's a question worth asking: why does a state-of-the-art vulnerability detection model score 68% on one benchmark and 3% on another?
Same model. Same task. Wildly different results.
The easy answer is "bad benchmarks." But that misses the more interesting point. The gap reveals something fundamental about how we've been thinking about vulnerability detection, and why our evaluation methods haven't caught up to reality.
The Data Leakage Problem
Older benchmarks like BigVul have a serious flaw - data leakage. A significant portion of test samples appear nearly identically in training data. Models aren't learning to find vulnerabilities, they're recognizing code they've memorized.
PrimeVul, developed by researchers at Columbia, UC Berkeley, and Google DeepMind, fixes this. It removes duplicates and enforces time-based splits, models train only on older code and get tested on newer vulnerabilities they've never seen. No shortcuts, no memorization.
That's when the 68% becomes 3%.
The model didn't get worse. We just removed its cheat sheet.

Functions vs. Codebases
But data leakage is only part of the story. There's a deeper issue that benchmark scores don't capture.
Finding a vulnerability inside a small, curated function where we already know something is wrong is a fundamentally different task than identifying that same issue buried in a real codebase.
Consider a SQL injection vulnerability. In a curated benchmark, the model sees a 15-line function with:
query = "SELECT * FROM users WHERE id=" + user_inputThe pattern is obvious. Easy classification.
In production, that same vulnerability might be split across a controller that accepts input, a service layer that passes it along, and a data access function three files away that builds the query. The vulnerable pattern is identical. The context required to find it is completely different.
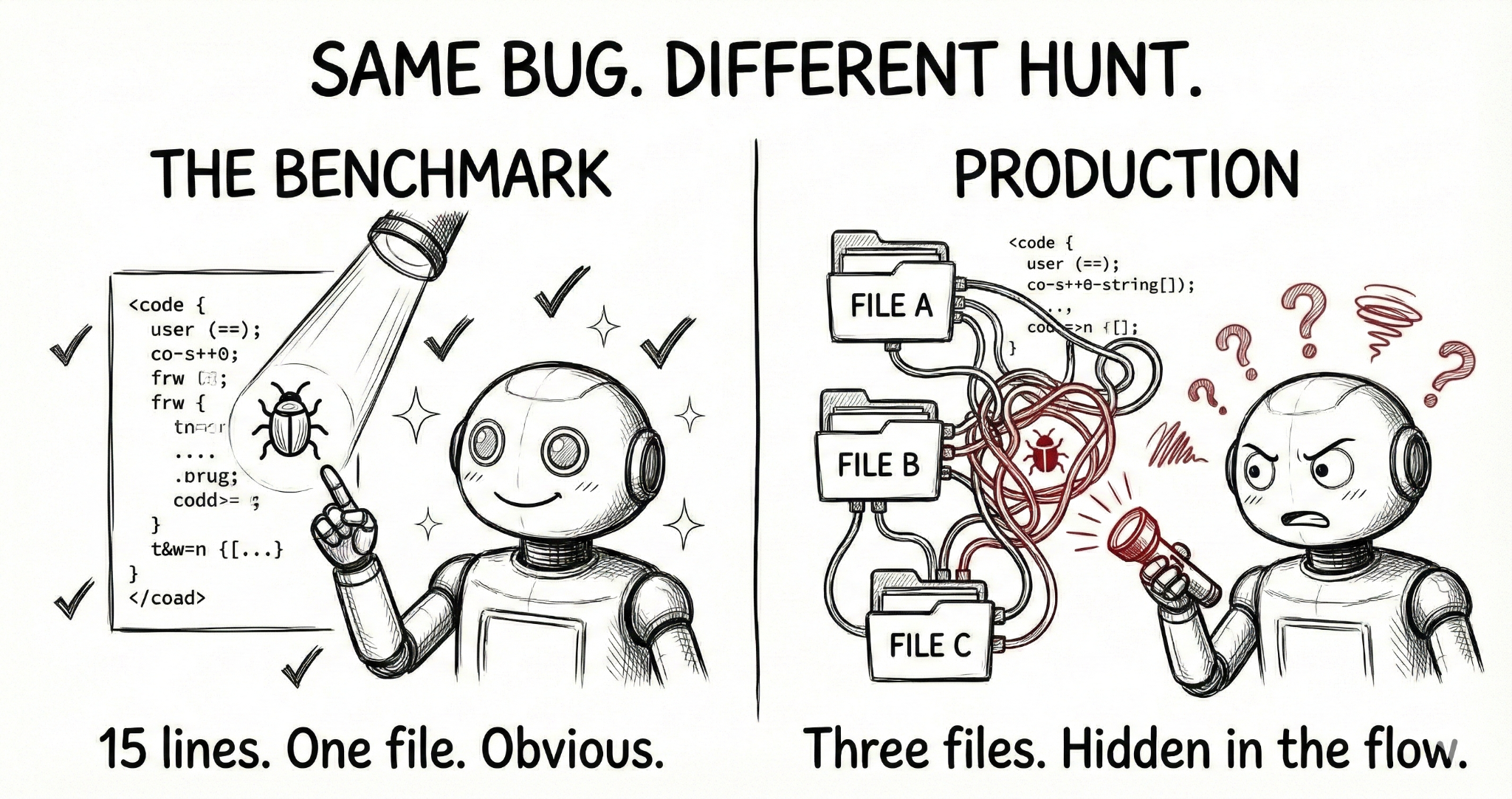
Current benchmarks are dominated by the first scenario: small, isolated examples where models succeed through pattern matching. Production codebases look like the second scenario, requiring context tracking, cross-file reasoning, and understanding how components interact.
When a model scores 68% on curated functions and 3% on cleaner data, it's not that one benchmark is "right" and the other "wrong." They're measuring different capabilities. The problem is we've been treating the first number as predictive of real-world performance when it isn't.
What Realistic Evaluation Would Look Like
A more meaningful benchmark might work like this: take a real repository with a known CVE and ask whether the model can find the vulnerability when it's buried across files, dependencies, and abstractions. Then compare that to detection on the same vulnerability presented as an isolated function.
That contrast would reveal how much performance depends on having context pre-extracted versus actually understanding code structure. My guess is the gap would be significant.
Some recent work moves in this direction. Benchmarks like JITVul test whether models can reason about vulnerabilities in their actual repository context, and early results show that even tool-equipped agents remain inconsistent at this task.

Where This Leaves Us
The vulnerability detection field has made genuine progress on reducing false positives. Fewer noisy alerts, better signal quality, more usable tools. That matters.
But false negativesthe 32% to 97% of vulnerabilities that slip through (depending on which benchmark you trust) remain under-measured. We've optimized for the metric that's easy to demonstrate while leaving the harder question mostly unaddressed.
The path forward isn't abandoning AI-powered detection. These tools have real potential. But realizing it requires benchmarks that reflect how vulnerabilities actually exist in production: distributed across files, dependent on context, invisible without cross-component reasoning.
That's not glamorous work. Building repository-scale evaluation infrastructure with real CVE ground truth is slow and ungrateful. But it's the work that determines whether these tools actually improve security or just improve our confidence while the hard problems remain unsolved.
The 68% vs 3% gap isn't a measurement error. It's showing us exactly where the real challenges remain.
Papers:
- PrimeVul (ICSE 2025): https://arxiv.org/abs/2403.18624
- JITVul (ACL 2025): https://arxiv.org/abs/2503.03586